
Pandas head() method explain in simple words
Let's understand the head() method offered by pandas in short with simple example.

So are you someone who's just beginning your journey as data analysts or maybe scientists and Pandas is what you came across for the first time.
And, I'm also very sure that if you're reading this article means you've not gone through any of Pandas related course or guide. So let me help you with that by telling what's Pandas actually?
What is Pandas library?
Pandas is a python library that offers us various method that can be use to turn messy datasets (dataframe) into cleaned and structured one.
Ensuring that, it's now ready and can be use for further analysis and visualization or taking one step further can also be use to train machine learning models.
Inshort, Pandas is like someone who cleans up messy dinner table and make it ready so others can have their food. And, cleaning or what we call it as preprocessing of data is must to be done before performing data analysis or training any model.
So that's all Pandas is. Although, it's not limited to three paras discussed above but as we are just here to discuss it's one method that is head() so we will just focus on it.
What is head() method in Pandas?
Quick definition ——
It is a method that helps us get an idea about how many and what sorts of column are there in the dataset , we are about to clean or analyze.
So basically, when we are about to perform preprocessing on any data we usually get a raw data. Totally unorganized and messy one, it is really tough to understand it. Like,
- what the dataset actually contains
So for that we can use head() method given by Pandas.
After using this method on dataset; it will return the first few rows with all the columns that dataset has in an tabular format.
So having all the columns known is important before starting with data analysis. And, I don't think so there's any need to tell , what role do columns plays in understanding data.
Can you imagine excel spreadsheets without columns?
How to use head() method?
Let's take an example .
Where first I'll show you how an unorganized dataset look like.
Just look at the below given picture..
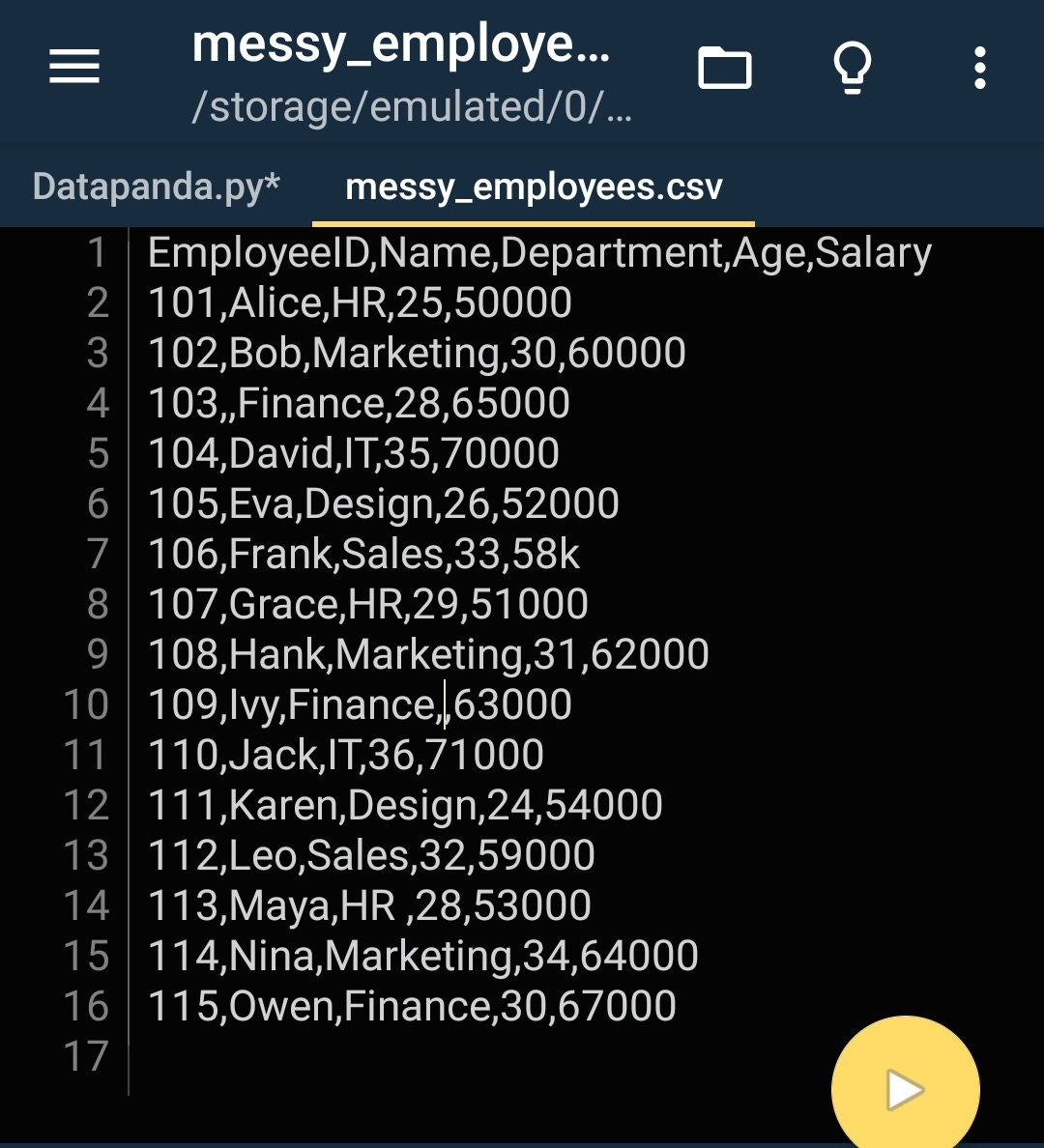
So can you please tell me that, Is it easy or hard to read. In this particular case it might feel easy as this csv data file is very small.
Even though it's small still it is not readable as well as not in the right format to track the corresponding rows and columns for the long go.
Now, we will use head() method and see how it will make this messy data digestible.
Just follow this simple python plus pandas code
#if pandas is not already been install please install it on your system.
#then, follow this code
import pandas as pd
df = pd. read_csv(“filepath”)
print(df.head(3))
#df in second line is nothing but just a variable.
#using read_csv() method, pandas will be able to read our messy .csv and then will transform it in tabular for and will store it in variable df. That's it. Now after running this you will get the data in perfect readable and more importantly changeable format.
This is the result you will get.
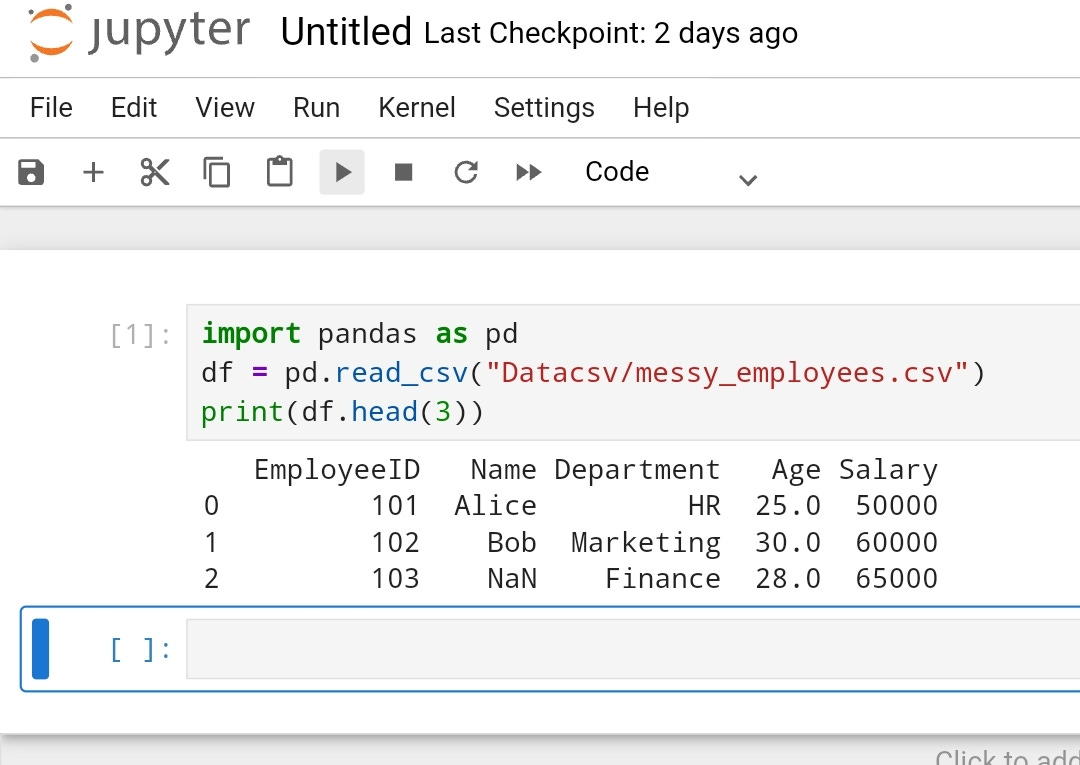
You might have notice why I have pass 3 in the brackets of head() method.
That 3 here, represent number of rows from top and so after running this code pandas will return first three rows with all the columns they're present in tha dataset. If you passed just 1 as an argument to head method, it will return just first row from the dataset but all the columns.
If you passed nothing then, by default pandas will show you first five rows.
Now, you may asked I want to see the rows from bottom. Like, I want to get an idea of how many rows are present in whole dataset.
How can I? Is there any method for that?
Yes, there's is another method just opposite to head() which is tail() method. You can just replace the head method with tail from above code and you'll start getting rows from bottom.
And, that's all for head() method. Hope you like this article. If yes, please like it and share it and I would definitely love to connect with you in comment section.